Paper: Dremel: A Decade of Interactive SQL Analysis at Web Scale
Introduction #
the main ideas we highlight in this paper are:
- SQL: simple SQL query to analyze nested data
- Disaggregated compute and storage: decouples compute from storage
- In situ analysis: different compute engines can operate on same piece of data
- Serverless computing: fully managed internal service
- Columnar storage
Embracing SQL #
Because SQL doesn’t scale, GFS and MapReduce became the standard ways to store and process huge datasets. However writing analysis jobs on these systems is difficult and complex. Dremel was one of the first systems to reintroduce SQL for Big Data analysis.
In Google, nearly all data passed between applications or stored on disk was in Protocol Buffers. Dremel's critical innovations includes first-class support for structured data. Dremel made it easy to query that hierarchical data with SQL.
Disaggregated storage #
Dremel started with shared-nothing servers and computation is coupled with storage.
In 2009, Dremel was migrated to Borg (cluster management) and replicated storage. It accommodate the growing query workload and improve the utilization of the service. However storage and processing are still coupled. Which means
- all algorithms needed to be replication-aware
- resizing server also need to move data around.
- Resources can only be accessed by Dremel.
Later Dremel was migrated from local disk to GFS. Performance was initially degraded. After lots of fine-tuning, disaggregated storage outperformed the local-disk based system. There are several advantages:
- improved SLOs and robustness of Dremel because GFS is fully-managed service.
- No more need to load from GFS onto Dremel server’s local disks.
- No need to resize our clusters in order to load new data.
Another notch of scalability and robustness was gained once Google’s file system was migrated from GFS (single-master model) to Colossus (distributed multi-master model).
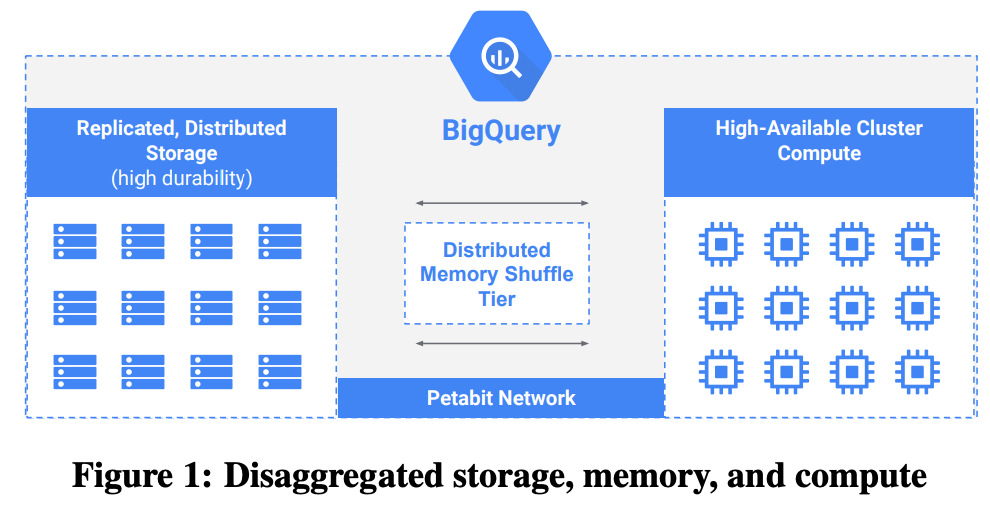
Disaggregated memory #
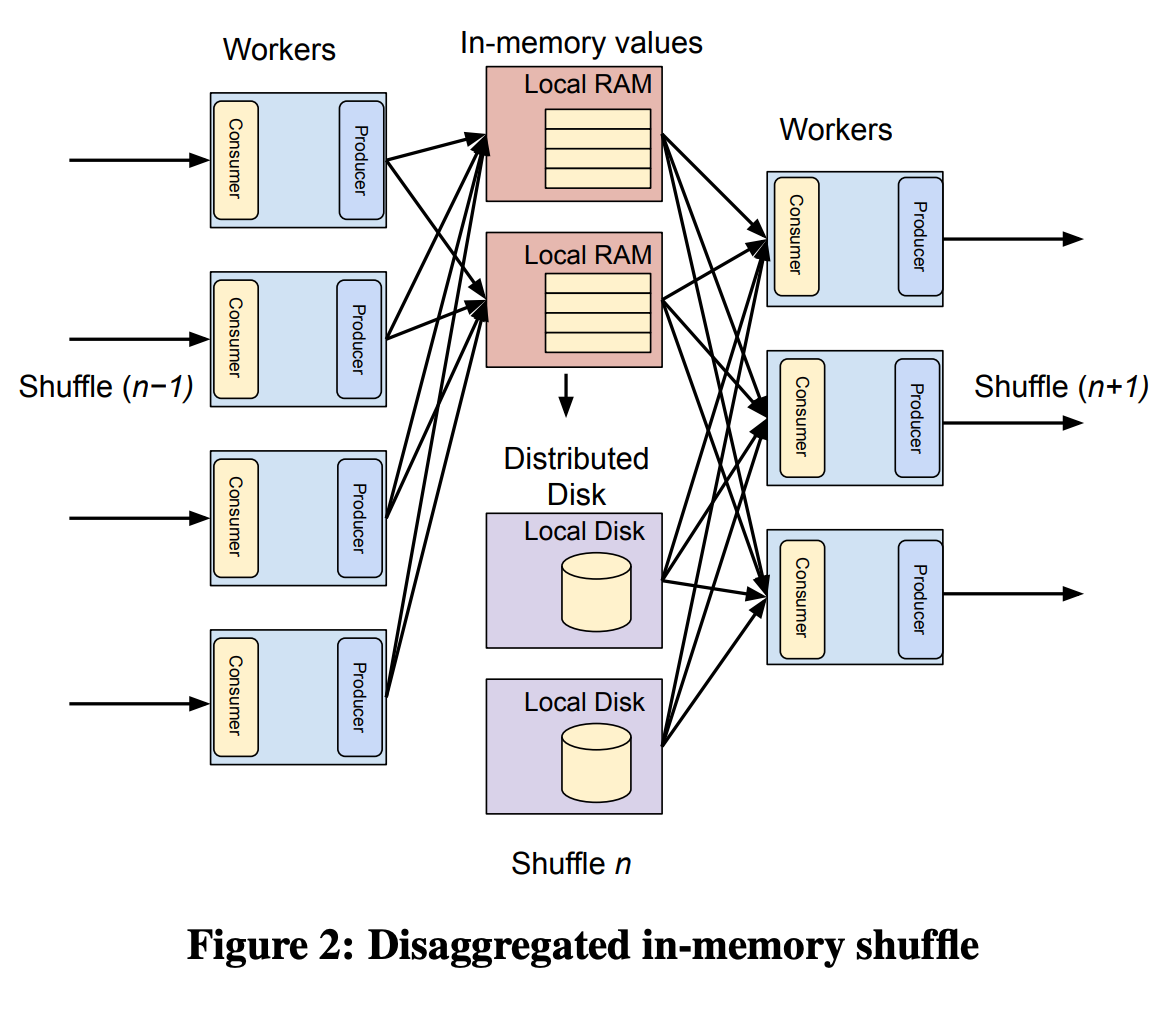
Dremel added support for distributed joins with shuffle utilizing local RAM and disk to store sorted intermediate results. However there is bottleneck in scalability and multi-tenancy due to the coupling between the compute nodes intermediate shuffle storage.
In 2014, Dremel shuffle migrated to a new shuffle infrastructure. Shuffle data were stored in a distributed transient storage system. Improved peformance in-terms of latency and larger shuffle and service cost was observed.
Observations #
Disaggregation proved to be a major trend in data management.
- Economies of scale
- Universality
- Higher-level APIs: Storage access is far removed from the early block I/O APIs.
- Value-added repackaging
In Situ Data Analysis #
The data management community finds itself today in the middle of a transition from classical data warehouses to a datalake-oriented architecture for analytics. The trend includes:
- consuming data from a variety of data sources
- eliminating traditional ETL-based data ingestion from an OLTP system to a data warehouse
- enabling a variety of compute engines to operate on the data.
Dremel’s evolution to in situ analysis #
Dremel’s initial design in 2006 was reminiscent of traditional DBMSs:
- explicit data loading was required.
- the data was stored in a proprietary format.
- inaccessible to other tools.
As part of migrating Dremel to GFS, Dremel open the storage format (as a library) within Google which has 2 distinguising properties: columnar, self-dsecribing. The self-dsecribing feature enables interoperation between custom data transformation tools and SQL-based analytics. MapReduce jobs could run on columnar data, write out columnar results, and those results could be immediately queried via Dremel. Users no longer had to load data into their data warehouse, any file they had in the GFS could effectively be queryable.
In situ approach was evolved in two complementary directions:
- adding file formats beyond original columnar format.
- expanding the universe of joinable data ( e.g. BigTable, Cloud Storage, Google Drive ).
Drawbacks of in situ analysis #
- users do not always want to or have the capability to manage their own data safely and securely
- in situ analysis means there is no opportunity to either optimize storage layout or compute statistics in the general case.
Serverless Computing #
Serverless roots #
- Most traditional DBMS and data-warehouse were deployed on dedicated servers.
- MapReduce and Hadoop uses virtual machines but are still single-tenant.
Three core ideas in Dremel which enable serverless analytics:
- Disaggregation of compute, storage and memory
- Fault Tolerance and Restartability
- each subtask are deterministic and repeatable
- task dispatcher may need to dispatching multiple copies of the same task to alleviate unresponsive workers.
- Virtual Scheduling Units
- Dremel scheduling logic was designed to work with abstract units of compute and memory called slots
Evolution of serverless architecture #
Dremel continued to evolve its serverless capabilities, making them one of the key characteristics of Google BigQuery today.
-
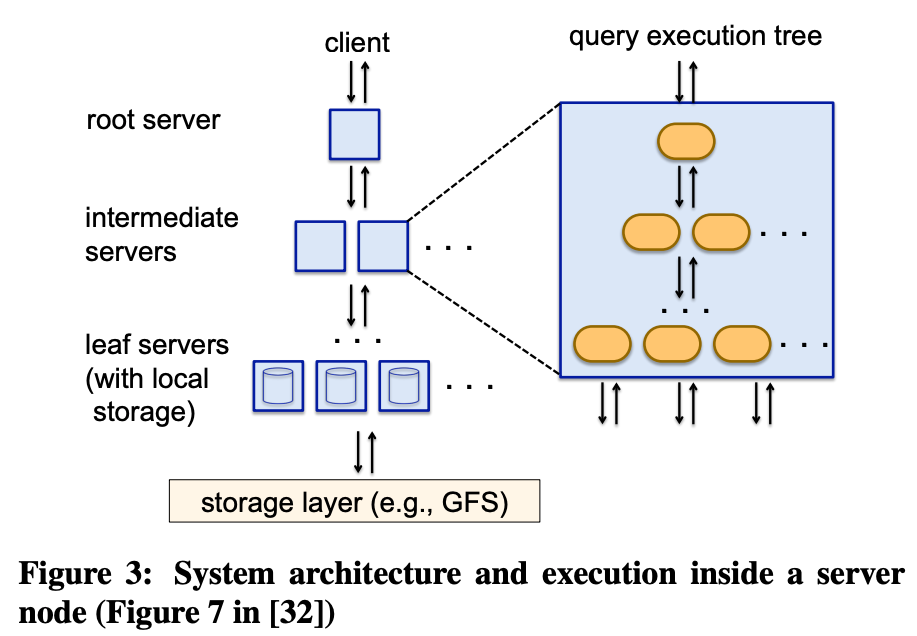
Centralized Scheduling
- The scheduler uses the entire cluster state to make scheduling decisions which enables better utilization and isolation. (Figure 3)
-
Shuffle Persistence Layer
- allow decoupling scheduling and execution of different stages of the query.
-
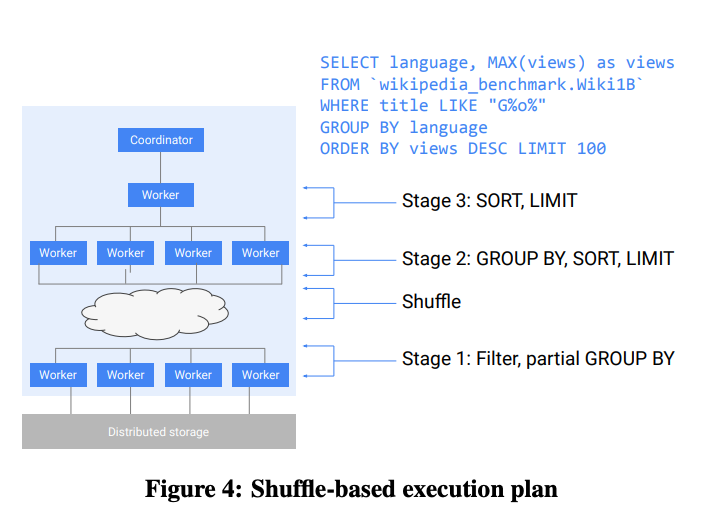
Flexible Execution DAGs
- query coordinator builds the query plan (tree) and send to the workers
- Workers from the leaf stage read from the storage layer and write to the shuffle persistence layer.
-
Dynamic Query Execution
- query execution plan can dynamically change during runtime based on the statistics collected during query execution.
Columar Storage For Nested Data #
The main design decision behind repetition and definition levels encoding was to encode all structure information within the column itself, so it can be accessed without reading ancestor fields.
- repetition level: specifies for repeated values whether each ancestor record is appended into or starts a new value
- definition level: specifies which ancestor records are absent when an optional field is absent.
In 2014, migration of the storage to an improved columnar format, Capacitor.
Embedded evaluation #
Capacitor uses a number of techniques to make filtering efficient
- Partition and predicate pruning
- Various statistics are maintained about the values in each column. They are used both to eliminate partitions that are guaranteed to not contain any matching rows, and to simplify the filter by removing tautologies
- Vectorization: Bit-Vector Encoding
- Skip-indexes
- Capacitor combines column values into segments, which are compressed individually.
- The column header contains an index with offsets pointing to the beginning of each segment.
- When the filter is very selective, Capacitor uses this index to skip segments that have no hits, avoiding their decompression.
- Predicate reordering
- Capacitor uses a number of heuristics to make filter reordering decisions, which take into account dictionary usage, unique value cardinality,
Row reordering #
- run-length encodings (RLE) in particular is very sensitive to row ordering.
- Usually, row order in the table does not have significance, so Capacitor is free to permute rows to improve RLE effectiveness.
- Capacitor’s row reordering algorithm uses sampling and heuristics to build an approximate model.
Interactive Query Latency Over Big Data #
latency-reducing techniques implemented in Dremel:
-
Stand-by server pool
-
Speculative execution
- small, fine-grained task
- duplicate tasks to prevent slow worker
-
Multi-level execution trees
-
Column-oriented schema representation
-
Balancing CPU and IO with lightweight compression
-
Approximate results
- Dremel uses one-pass algorithms that work well with the multi-level execution tree architecture.
-
Query latency tier
- The dispatcher needed to be able to preempt the processing of parts of a query to allow a new user’s query to be processed.
-
Reuse of file operations
- bottleneck for achieving low latency as thousands of Dremel workers send requests to the file system master(s) for metadata and to the chunk servers for open and read operations.
- The most important one: reuse metadata obtained from the file system by fetching it in a batch at the root server and passing it through the execution tree to the leaf servers for data reads.
-
Guaranteed capacity
- a customer could reserve some capacity and use that capacity only for latency-sensitive workloads.
-
Adaptive query scaling